Using Wikidata to structure Welsh placename data
The text we read when we view a web page, a blog or a journal article is full of rich and valuable information. Our brains are very good at processing and making sense of words in the context in which they are presented. We can tell when a word is a placename because we understand the sentence around it, and are expecting to see a place name. Also, we often already know the name of the place and could describe it in further detail from memory.
If computers could understand text as we do then they could be super useful in helping us find and understand information better. Technology such as Named Entity Recognition (NER), where machines are trained to recognise things like people, places and organizations by analyzing a whole text, is increasingly being used to turn plain text into a structured network of ‘things’, and this means machines can make a more complex analysis of text, much as we do.
As part of our ongoing Welsh Place Names project, which is funded by the Welsh Government, we were keen to explore how these new technologies and methodologies might be applied to Welsh language texts and to our own collections. With millions of pages of journals, newspapers and books already digitised, how might this technology help us improve our services for better research, discovery and interpretation?
Named Entity Recognition
The Dictionary of Welsh Biography was chosen for this experiment, as a (fairly) manageable corpus of about 5000 articles, packed with information about people and places. Most placenames have actually already been tagged as such in the mark-up for each page, which gives us a good benchmark for NER models to aim for, and a big corpus of place names for further analysis.
Identifying which words are placenames is the first step in this process. Those names then need to be reconciled against a database of names, which can give us access to a deeper, multilingual understanding of the place.
English language NER tools struggle to identify places in Welsh text for a number of reasons. Firstly they are not trained to understand grammatical mutations present in the Welsh language. For example, ‘Tregaron’ is the name of a town, in English and Welsh, however, if the text reads ‘yn Nhregaron’ it will not recognise the name due to the mutation (treiglo) of the first letter. Secondly, many placenames are different in Welsh (e.g. Cardiff is Caerdydd) and so models trained on English text simply won’t have the word in their vocabulary. Several English models were tested and many either didn’t recognise names, or assumed they were names of people.
We therefore experimented with ‘Cymrie’, part of the Welsh Government funded Welsh Natural Language Toolkit.

This was able to extract a number of Welsh placenames, including many with mutations. The text of 5 articles was analyzed in detail. On average the tool was able to extract approximately 67% of placenames. Of those place names identified, only 2% were not in fact places.
Some of the placenames it was unable to recognise were tagged as people or organizations, though this was at a lower rate than the English language model.
Reconciling the Data
Knowing what words are names of people or places is useful only to a point, because we still know nothing more than ‘it’s a place’. For the data to be really useful we need access to more information about each place, such as its name in other languages, its location on a map and the county, country or continent it is part of. We can then apply a unique identifier to each place and they become unique data entities.
To do this we need to take our long list of place names and attempt to reconcile them against a database which holds more information about them. In our case we are using Wikidata, which is home to one of the largest corpus of Welsh place names available. Wikidata is free for anyone to reuse and is structured as linked data.
The Dictionary of Welsh Biography contains around 80,000 instances of place names. Due to the practicalities of working with such a large dataset, I opted to work with the first 46,000 tagged places.
The tags in the Welsh Biography code often contained more than just the placename. They commonly included a Grid reference, the type of place (city, village etc) and the relation to that place being discussed in the article.
Obviously having all this information to hand makes the reconciliation process far more likely to succeed. As NER technology improves, it should be able to imply much of this information, by understanding the wider context in which the place name appears, but for now, we must accept that without this additional information, this process would have a far lower success rate.
Using Open Refine’s reconciliation tool we were able to compare our list of placenames to Wikidata. The software’s algorithm looks for similarities in spelling but also considers the likelihood of a match based on the popularity of its content. By transforming the grid references from our data into coordinates we were also able to instruct Open Refine to score matches based on their proximity. Places with matching names and proximity of less than a kilometre were mostly matched automatically. Our data on the type of place was also used to help the software make a judgement.
In order to give the reconciliation process the best chance of success some initial cleaning was done to remove mutations from the text. Much of this could be done using a series of transformations such as;
- Nghaer – Caer
- Nhre – Tre
Others require knowledge of the language and human input in order to avoid the corruption of other names. For example ‘Lan’ cannot be automatically changed to ‘Llan’ without corrupting other names such as ‘Lanishan’.
Other issues included the use of English language names in the Welsh text;
- New England (Lloegr Newydd)
- Bristol (Bryste)
- Saint Brides (Sant y Brid)
There were also a number of placenames which had suggested matches, but had a high chance of also being the name of a property. For example;
- Trawscoed (house, estate and community)
- Cilgwyn (village in Powys, Gwynedd, Carmarthenshire AND a gentry house)
- Ty-coch (area near Swansea and common house name)
short of reading each article in order to make a decision, there is currently no way to match such places with any certainty. However, such a manual process could be easily gamified as a crowd-sourcing task. Undertaking such tasks would also create training data for improving NER in the future.

The result was an initial match of 25,000 names, to which a further 2000 were quickly added following a human review of high-scoring match suggestions. These matches include 2208 unique place names. Beyond this, an increasing amount of time would be required to match entries manually.


Utilizing the enriched data
Now that we have aligned our placenames to Wikidata entries for those places, we have access to a wealth of additional information. This extra information can be summarized in several categories;
- Persistent ID – Being able to assign a unique Qid to each placename means we can treat each one as a unique entity, even if there are examples of multiple places with the same name.
- External ID’s – Wikidata collects persistent Id’s from other institutions which hold information about the subject. This helps align and enrich data across multiple datasets.
- Contextual information – This includes links to Wikipedia articles, openly licenced images and references to other authoritative works.
- Structured Data – Wikidata contains a linked, structured ontology about its items, So places are linked to their administrative hierarchy and every other item in the dataset with a statement about that place.
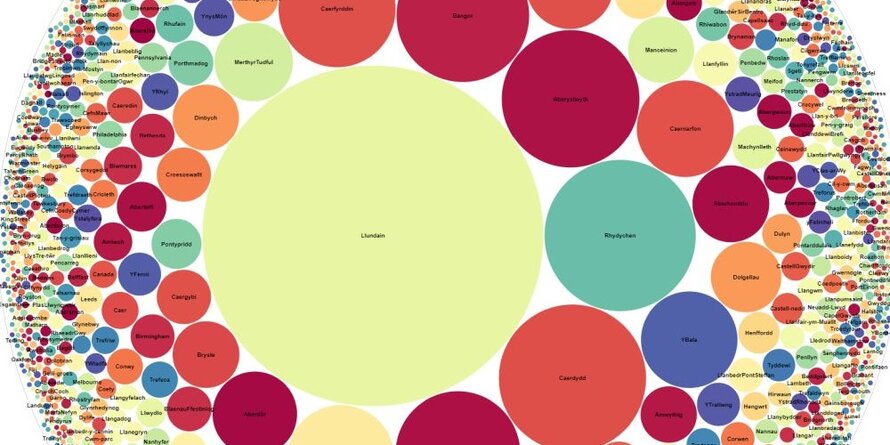
This allows us to better understand the connections between people and place. In the example below a computer is able to understand that two people are connected to several common places through reference to these places in their Welsh Biography articles. The colour and thickness of the connecting strands also indicate the frequency of these references within each article.

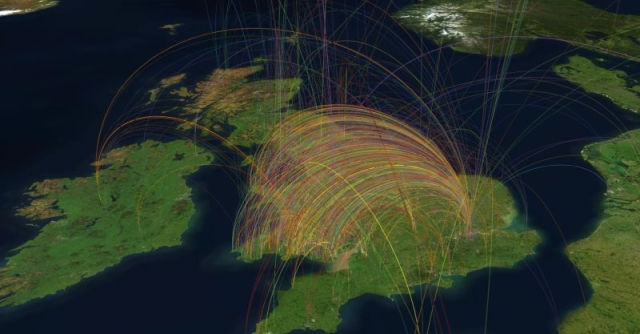
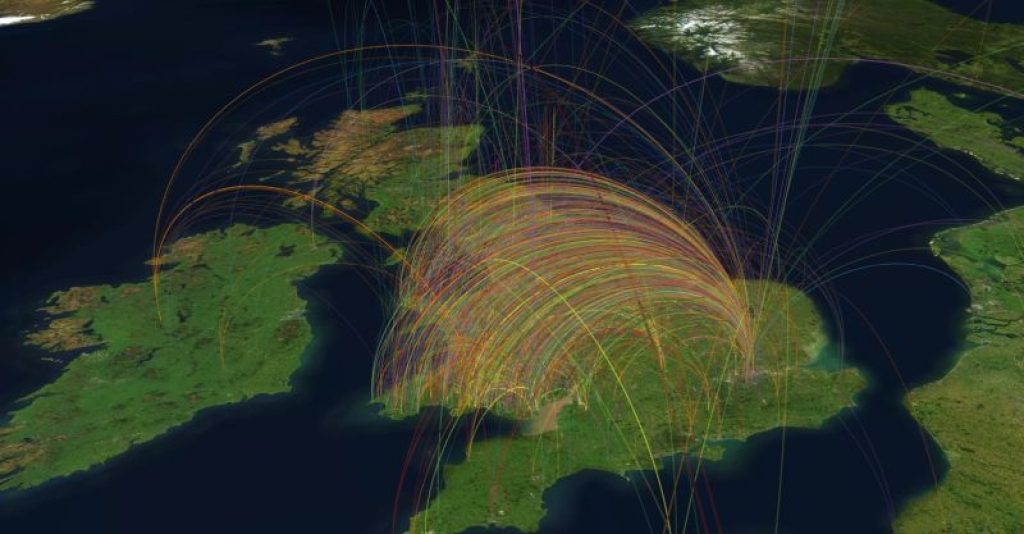
When this approach is scaled up to the whole corpus we can see a hugely complex web of interconnections between people and places.

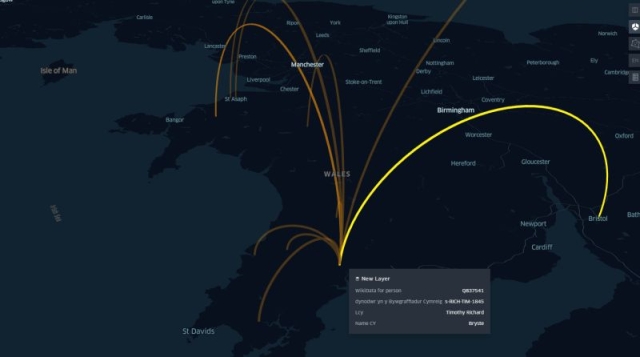
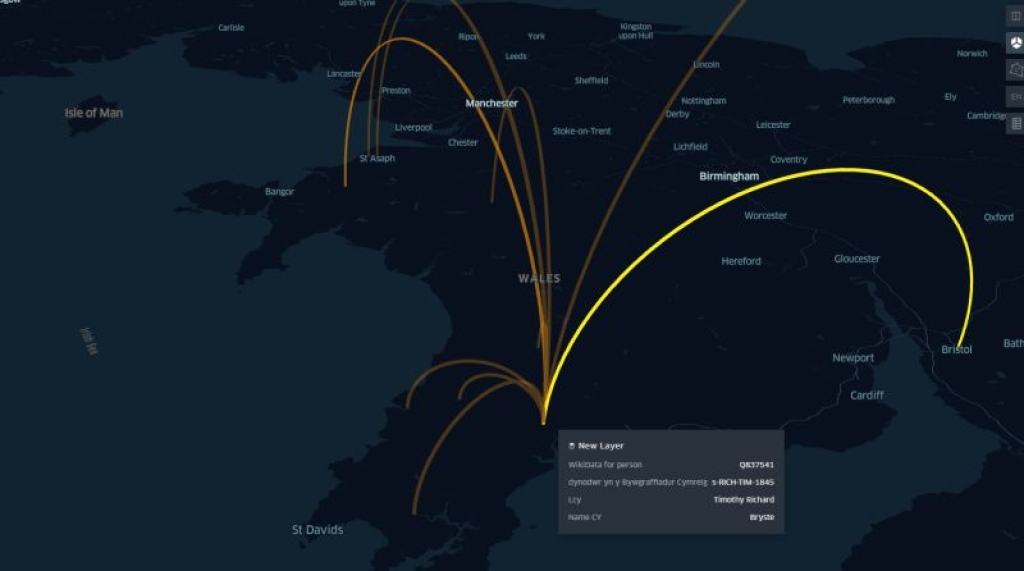
And since we now have access to coordinates for all our places, we can visualize these connections on a map. Below we see visualisations for an individual and for the whole collection using people’s birthplace as a starting point, connected to all other places mentioned in their articles.
{kind=link}
{kind=link}
Using the contextual information in place name tags we can make more granular queries, such as links between the place of birth and places of education mentioned in their articles. This highlights clear correlations to major centres of learning and further demonstrates the research potential of the data.

Conclusions
In conclusion, existing technology can accurately identify around 60-70% of Welsh place names in digital text. Training more advanced A.I. algorithms using larger place name vocabularies and a bigger corpus of training data may help to increase this percentage even further. Undertaking this process at scale would allow for further research and reconciliation work to take place and would also help to improve search and discovery functionality, but it does not identify unique places, only the instance of a place name.
In order to create notable benefits, the data must be reconciled against a database with data about specific places. With many duplications in place names in Wales and around the world this step is vital in creating connections to the correct places. It would seem that we don’t yet have the technology to automate this, in any language, with a high level of certainty. Several examples of pipelines being developed in order to identify entities in text and reconcile directly against Wikidata or other large datasets do exist, including a project by a colleague here at the National Library (link). However, they have faced the same kind of challenges.
Where additional supporting data already exists, like our Dictionary of Welsh Biography example it is possible to automate this to some degree but there is still a significant margin for error without human input.
Whilst accurate and complete identification of entities from a text is not yet possible, these processes offer value, as a stand alone activity or as part of a multidisciplinary approach, as a way of improving understanding of a text and improving search and discovery services for users.
Importantly, the ability to undertake this work on Welsh language texts is only possible with the continued development, adaptation and improvement of new technologies, and the availability of Open Access data sources such as Wikidata and Open Street Map as well as large corpora of Welsh language text for training machine learning algorithms.
Jason Evans
Open Data Manager
Category: Article