
Well resourced, and widely spoken languages like English, Spanish or Chinese have no shortage of human content creators. Whether it's volunteers writing on Wikipedia, commercial publishers or content produced by the state or public sector, people can usually get access to the information they need in their own language.
For smaller, and minority languages this becomes more of a challenge. The state has less resources, commercial opportunities are limited and less speakers means less volunteers. English Wikipedia had nearly 39,000 active editors last month and 826 admins. Whilst Welsh Wicipedia punches above its weight in terms of the size of the Welsh speaking population those figures are somewhat lower, with 29 active editors and a handful of admins.
So, whilst there is lots of effort to increase the number of human contributors, through schools, community groups and universities for example, there is only so much that can be done and that puts Welsh speakers at a disadvantage. At the National Library of Wales we believe that everyone has an equal right to access knowledge in Welsh or English and so we have been exploring ways we can support the growth of the Welsh Wicipedia, both through community activism and technological innovation.
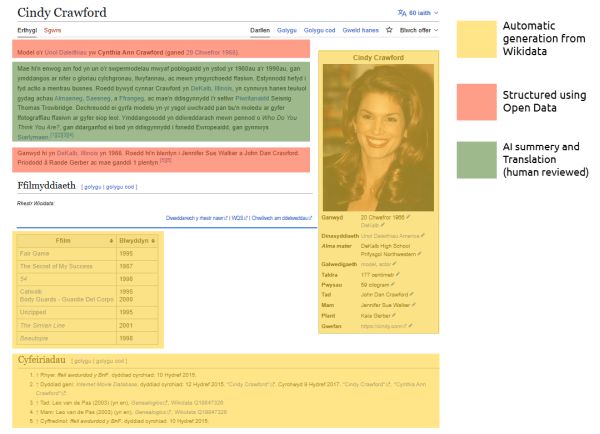
There is an established practice within the Wikimedia community of creating so-called ‘Bot’ generated articles. These take open data and structure it into standard sentences to form very short and concise articles at scale. And whilst this increases the number of articles, they are often short and lack the contextual information and nuance needed to fully convey the importance of a subject. So we developed a hybrid approach, augmenting these bot articles with a short summary written by real people. This meant publishing smaller, but richer batches of articles about a given subject, such as places or a collection of biographies, whist still reducing the human effort needed to create new content at scale.
With the rise of AI we see obvious challenges, but also opportunities. Wikipedia remains the most visited Welsh language website with millions of views each month. It's also widely documented that Wikipedia content is an important training resource for Large Language Models (LLMs) and this is important in the Welsh context both in terms of quality of information produced by AI and also the ability of models to communicate effectively in Welsh.
So with funding from Welsh Government’s Cymraeg 2050 programme we have begun exploring how AI can be used responsibly to help increase the amount of useful and accurate knowledge available in Welsh on Wikipedia.
With a target of creating 1000 new Welsh biographies about notable individuals in the film, television and music industry I set about developing an approach which harnessed AI to reduce the human effort needed, whilst maintaining human oversight and accountability for all the content.
Articles were broken down into four main parts.
- Infobox and images were populated directly from Wikidata (Wikimedia’s open database) using existing templates on Welsh Wicipedia. Wikidata is also a multilingual platform so we are able to use this source to pull in information in Welsh without the need for translation.
- Key biographical information such as place of birth, death and education and key dates, along with relevant references, are extracted from Wikidata and structured as sentences for use in articles.
- Lists, such as filmographies were again, generated using Wikidata. For these we used a tool called “Listeria”. Like infoboxes, if the source data on Wikidata changes, these changes will be reflected in the article automatically. So if an actor appears in a new movie, their filmography will be updated automatically with the new information.
- AI summary and translation of English language Wikipedia articles. We chose content where articles were missing in Welsh but present in English, and developed a detailed series of prompts for ChatGPT to follow. The AI summarized certain content from English articles and produced a Welsh language summary in about 100-150 words.
It’s worth noting that AI also proved useful in collecting all the necessary data together. LLMs are very good at performing technical requests, such as producing scripts to extract the text required from English Wikipedia, and transforming data into the desired formats. ChatGPT was even able to advise on how to structure my prompt for summarizing the English content. Much like the process of creating the articles themselves, AI is harnessed to speed up manual processes rather than replace human involvement.
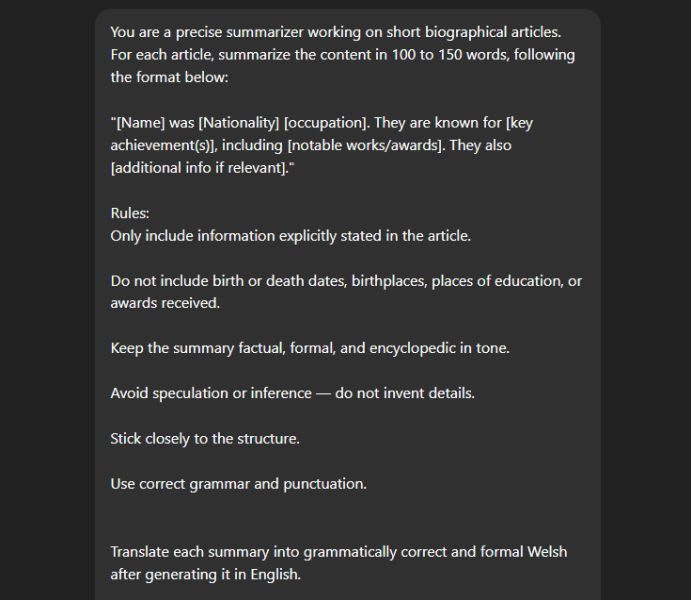
Once I had extracted the relevant text from English Wikipedia via the MediaWiki API, I developed a prompt for creating the summaries. The prompt stressed the importance of only summarizing information that was clearly part of the English article, and the importance of preserving Wikipedia’s encyclopedic tone. The prompt also instructed the AI not to include the biographical information we already had access to from Wikidata. Using reliable data as the source for these key facts reduced the risk of errors in the AI output, and meant there was less AI generated text to have to review and check.
Initial tests showed that when instructed to summarize directly into Welsh, the standard of Welsh was poor at times. This improved greatly when the model was instructed to summarize and translate in two separate steps.
Chat GPT processed the summaries in batches. I used the web interface however, the GPT API could have also been used to streamline this process. Each summary was then proof read with attention given to factual accuracy and grammatical correctness. There were a very small number of factual inaccuracies which seemed to be the result of misinterpretation of the original text. I did not detect any hallucinations or any information not found in the source text.
Most of the corrections required related to issues with the Welsh translation. In some places the translation was too literal. For example it frequently translated “Silent films” as “Ffilmau tawel” (Quiet films). There were other examples where the Welsh was technically correct but sentences flowed poorly. Some of these issues were repeated patterns across all the articles, which meant they could be corrected en-mass. Other issues needed manual intervention at an article level.
Once all the texts were checked all the different elements of the articles were pulled together using AutoWikiBrowser - a powerful tool for batch editing Wiki content. Sample articles were then published for community review. And this highlighted a few other issues, such as inconsistent use of terminology and a few more grammatical errors. These were all addressed, and consensus from the Welsh editing community was given before the main batch of articles was published.
Almost all of the 1000 texts required some small corrections, and some might argue that this is proof that the AI approach doesn't work in this context. However the time required to construct and check these articles using the process described above was a fraction of the time it would have taken to write each article from scratch. It does demonstrate very clearly that the creation of new encyclopedic content, or even the transfer of knowledge from one language to another, cannot currently be fully automated. AI gives us a powerful suite of tools to aid the dissemination of knowledge by living, breathing people. It does not replace the important work that Wikipedia volunteers do, it simply makes it a little easier.
At the National Library of Wales our approach to the use of AI is centered on the importance of having a human in the loop, and reinforcing the operator's accountability for any AI output. But with care we believe that these new technologies can help engage more people with Welsh language content and simultaneously help to develop the corpus of Welsh content needed to train AI models to understand and communicate better in the Welsh language.
Category: Article